





Китай интеллектуальные алгоритмы завод
Когда слышишь про 'китайские интеллектуальные алгоритмы', сразу представляются какие-то магические black-box системы. На деле же 90% проектов — это адаптация классических методов под специфику производства. Вот, к примеру, в ООО Аньхуэй Чжихуань технологии мы десять лет назад начали с простых нейросетей для диагностики вибрации оборудования, а сейчас уже внедряем гибридные архитектуры.
Эволюция подхода к промышленным алгоритмам
Помню, как в 2015 пытались применить готовые библиотеки машинного обучения к данным с вибродатчиков. Результат был удручающим — точность не превышала 60%. Оказалось, сырые сигналы нужно предварительно обрабатывать специальными фильтрами, которые мы разработали на основе двадцатилетнего опыта в акустике.
Сейчас в энергетическом секторе используем каскадные модели: сначала традиционные методы анализа спектров, потом уже интеллектуальные алгоритмы для классификации дефектов. Это снизило количество ложных срабатываний на 43% по сравнению с 'чистыми' AI-решениями.
Кстати, на сайте https://www.zhkjtec.ru есть кейс по мониторингу турбин — там как раз показан этот гибридный подход. Не идеальная реализация, но работающая в условиях ограниченных вычислительных ресурсов.
Проблемы интеграции на производстве
Металлургические предприятия — отдельный вызов. Высокие температуры и вибрации постоянно выводят из строя сенсоры. Пришлось разрабатывать алгоритмы, способные работать с частично повреждёнными данными. Не то чтобы мы полностью решили эту проблему, но сейчас система выдаёт предупреждения при degradation сигнала.
В нефтехимии столкнулись с противоположной ситуацией — избыток данных. Десятки тысяч датчиков генерируют такой объём информации, что стандартные методы просто не справляются. Пришлось внедрять распределённые вычисления прямо на edge-устройствах.
Самое сложное — объяснить технологам, почему алгоритм принял то или иное решение. До сих пор используем упрощённые диаграммы влияния признаков, хотя в теории есть более точные методы.
Кейс: система технического зрения для автомобильной промышленности
В 2021 запускали проект по контролю качества сварных швов. Камеры фиксировали дефекты, но алгоритмы постоянно путали блики с трещинами. Перепробовали три разных архитектуры свёрточных сетей, пока не остановились на модификации U-Net с дополнительным модулем внимания.
Интересный момент: оказалось, что для обучения нужно не менее 5000 размеченных изображений каждого типа дефектов. Сбор таких данных занял почти полгода — производители неохотно делились браком.
Сейчас система внедрена на двух заводах, но требует постоянной донастройки. Каждый новый тип кузова приходится дообучать на 200-300 примерах. Не идеально, но уже лучше, чем ручной контроль.
Адаптация под российские условия
Когда начинали работать с угольными шахтами, столкнулись с тем, что зарубежные аналоги наших систем не учитывали специфику местных условий. Пришлось полностью перерабатывать подход к калибровке оборудования — например, добавлять компенсацию для работы при низких температурах.
В цветной металлургии вообще пришлось разрабатывать custom-решения для каждого завода. Универсальные интеллектуальные алгоритмы показали эффективность всего 55-60%, тогда как специализированные достигают 85%.
Сейчас экспериментируем с transfer learning — пытаемся использовать наработки из энергетического сектора в металлургии. Пока результаты нестабильные, но в некоторых случаях удаётся сократить время внедрения на 30%.
Перспективы и ограничения
Главный вывод за последние годы: не существует универсального решения. Даже в рамках одного завода разные участки требуют разных подходов. Сейчас разрабатываем модульную систему, где можно комбинировать методы в зависимости от задачи.
Серьёзным ограничением остаётся качество данных. Даже самые продвинутые алгоритмы не работают с зашумленными сигналами. Приходится параллельно совершенствовать аппаратную часть — например, разрабатывать специальные антивибрационные крепления для датчиков.
Если говорить о будущем, то вижу потенциал в ensemble-методах, сочетающих физические модели и машинное обучение. Но это требует пересмотра всей архитектуры систем мониторинга — эволюционный подход здесь не сработает.
Соответствующая продукция
Соответствующая продукция

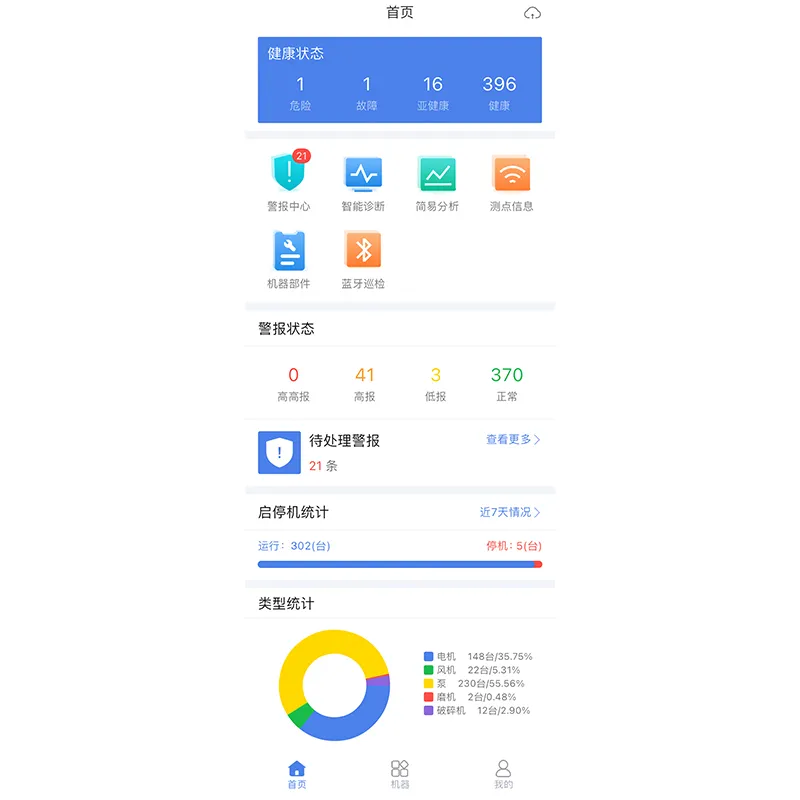
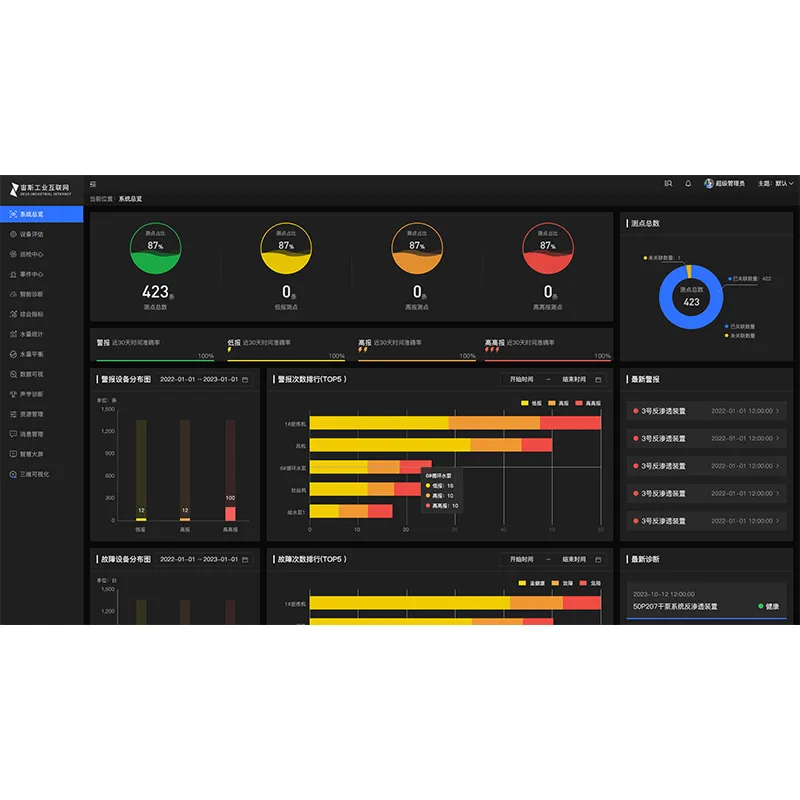

Самые продаваемые продукты
Самые продаваемые продукты-
 ZHY-1101(D)Взрывозащищенный и искробезопасный проводной регистратор данных
ZHY-1101(D)Взрывозащищенный и искробезопасный проводной регистратор данных -
 ZHW803P 3-осевой беспроводной встроенный датчик вибрации и температуры
ZHW803P 3-осевой беспроводной встроенный датчик вибрации и температуры -
 VS301 Акустический датчик вибрации и температуры
VS301 Акустический датчик вибрации и температуры -
 YHC12 Искробезопасный сборщик данных для горнодобывающей промышленности
YHC12 Искробезопасный сборщик данных для горнодобывающей промышленности -
 ZHY1101 5G -версия многофункционального проводного блока сбора данных
ZHY1101 5G -версия многофункционального проводного блока сбора данных -
 GBY1000W Беспроводной датчик вибрации для применения в горнодобывающей промышленности
GBY1000W Беспроводной датчик вибрации для применения в горнодобывающей промышленности -
 ZHY601(T) Проводной датчик вибрации всех частот
ZHY601(T) Проводной датчик вибрации всех частот -
 ZHW2001D Взрывозащищенный и искробезопасный беспроводной сборщик данных
ZHW2001D Взрывозащищенный и искробезопасный беспроводной сборщик данных -
 ZHW2001 Беспроводной регистратор данных
ZHW2001 Беспроводной регистратор данных -
 YJC127W Взрывозащищенный и искробезопасный беспроводной регистратор данных для использования в шахтах
YJC127W Взрывозащищенный и искробезопасный беспроводной регистратор данных для использования в шахтах -
 ZHW801 Беспроводной интегрированный датчик вибрации и температуры
ZHW801 Беспроводной интегрированный датчик вибрации и температуры -
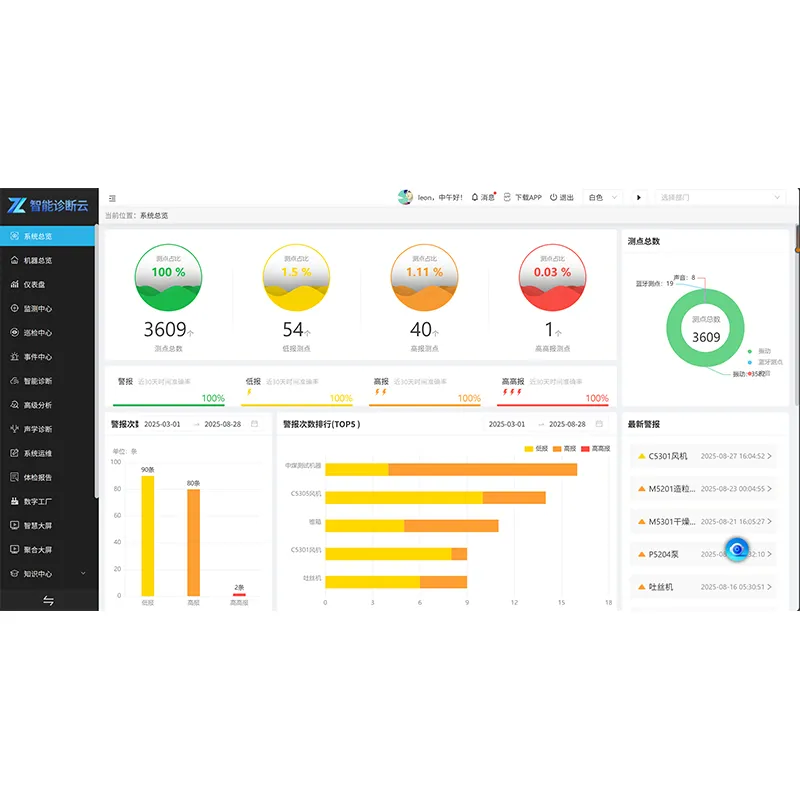 Облачная платформа диагностики машинного интеллекта
Облачная платформа диагностики машинного интеллекта
Связанный поиск
Связанный поиск- Китай цель цифрового двойника основный покупатель
- Динамический мониторинг оборудования поставщик
- Китай мониторинг состояния промышленного оборудования основный покупатель
- Китай проводной датчик для мониторинга акустической сигнатуры поставщик
- Мониторинг вентиляторов производитель
- Китай диагностика и анализ неисправностей
- Прогнозирование и диагностика неисправностей производители
- Китай мониторинг опасных газов основный покупатель
- Китай сборщик данных поставщик
- Китай интеллектуальное управление устойчивым состоянием основный покупатель