





Интеллектуальный мониторинг устройств завод
Недавно столкнулся с интересной задачей – внедрение системы интеллектуального мониторинга устройств завод на крупном металлургическом комбинате. И, знаете, что сразу бросилось в глаза? Огромное количество решений на рынке, но мало, которые действительно решают проблемы, а не просто генерируют отчеты. Часто компании гонятся за 'головной болью' - сложной аналитикой, игнорируя базовые, но критически важные вещи: своевременное обнаружение аномалий, прогнозирование отказов, оптимизацию режимов работы оборудования. И вот мы начинаем копаться в данных, которые, по сути, уже есть, но они разбросаны по разным системам, в разных форматах. Это уже первая 'ловушка', о которой часто не задумываются при планировании подобных проектов.
Проблема разрозненности данных
Самая большая проблема, с которой мы сталкиваемся при внедрении систем мониторинга оборудования – это разрозненность данных. У нас в типичном заводском окружении – датчики вибрации, температуры, давления, расхода, частоты вращения, данные с ПЛК, SCADA, системы управления технологическим процессом (АСУ ТП)... Всё это, как отдельные острова, не связанные между собой. Получается, чтобы получить полную картину, нужно собирать данные из десятков источников, которые часто используют разные протоколы и форматы. Это, конечно, не проблема техническая, а скорее организационная и требующая значительных усилий по интеграции. Мы часто начинаем с интеграции с существующими системами, что само по себе – сложный и дорогостоящий процесс. Попытка сразу интегрировать все системы – это часто путь к провалу. Лучше выделить ключевые, наиболее критичные для мониторинга параметры, и постепенно расширять охват.
Возьмем, к примеру, ситуацию с турбо-компрессором. Вибрация – это один параметр, температура подшипников – другой, давление масла – третий. Если мы смотрим на каждый параметр отдельно, то, возможно, не увидим всей картины. Но если мы объединим эти данные в единую систему и сможем построить корреляционные модели, то сможем выявить закономерности и предсказать возможные отказы. И это уже совсем другая история.
Интеграция и выбор платформы
Выбор платформы для интеллектуального анализа данных** – это тоже вопрос, требующий тщательного подхода. Есть масса решений – от готовых продуктов с предустановленными алгоритмами до открытых платформ, требующих разработки собственных алгоритмов. Готовые решения, как правило, проще и быстрее в настройке, но могут не подходить под специфические требования конкретного предприятия. Открытые платформы дают больше гибкости, но требуют наличия квалифицированных специалистов, способных разрабатывать и поддерживать алгоритмы. Мы часто рассматриваем варианты на основе Apache Kafka, Spark, и различных библиотек машинного обучения (scikit-learn, TensorFlow, PyTorch). Это, конечно, требует серьезной экспертизы, но позволяет создавать решения, которые идеально подходят под конкретные задачи.
Один из распространенных ошибок – это завышенные ожидания от готовых решений. Не стоит надеяться, что платформа сама по себе решит все проблемы. Необходимо понимать, что интеграция, настройка, обучение моделей – это трудоемкий процесс, требующий значительных ресурсов. Часто приходится дорабатывать готовые алгоритмы или разрабатывать собственные, чтобы добиться желаемого результата. Это, безусловно, увеличивает стоимость проекта, но позволяет получить более эффективное решение.
Реальный пример: предсказание отказов подшипников
В одном из наших проектов мы занимались мониторингом состояния подшипников** в электродвигателях. Изначально мы собирали данные о вибрации, температуре и давлении масла. Использовали систему на базе MQTT для сбора данных с датчиков. На платформе, построенной на основе Kafka и Spark, разработали алгоритмы машинного обучения, которые позволяли выявлять аномалии в данных и предсказывать возможные отказы. Первоначально алгоритм выдавал много ложных срабатываний, но после настройки параметров и добавления новых признаков (например, скорости вращения вала) точность предсказаний значительно возросла. В итоге, благодаря нашей системе, удалось предотвратить несколько серьезных отказов оборудования, что принесло значительную экономию предприятию.
Важно понимать, что для успешной реализации проекта по прогнозированию отказов оборудования необходимо иметь качественные данные и глубокое понимание работы оборудования. Без этого любые алгоритмы машинного обучения будут малоэффективны.
Проблемы масштабируемости и хранения данных
Еще одна проблема, с которой мы часто сталкиваемся – это масштабируемость системы. По мере увеличения количества датчиков и оборудования объем данных растет экспоненциально. Необходимо предусмотреть возможность масштабирования системы, чтобы она могла обрабатывать большие объемы данных без потери производительности. Мы часто используем облачные технологии (AWS, Azure, Google Cloud) для хранения и обработки данных. Это позволяет нам избежать проблем с инфраструктурой и масштабировать ресурсы по мере необходимости. Хранение данных – это отдельная тема, которую нужно тщательно продумать. Необходимо выбрать подходящую базу данных (например, TimeScaleDB, InfluxDB) и оптимизировать ее для хранения временных рядов данных. Без грамотной организации хранения данных, система может быстро стать неработоспособной.
Иногда, мы видим ситуации, когда компании собирают огромные объемы данных, но не имеют возможности их эффективно использовать. Это называется 'data overload'. Лучше сфокусироваться на тех данных, которые действительно важны для решения конкретных задач, и не пытаться хранить все подряд. Ключевой момент – это определение приоритетов и выбор правильных алгоритмов анализа данных.
Опыт, который не стоит повторять
Однажды мы пытались использовать готовое решение для визуализации данных** из систем мониторинга. Это был очень дорогой продукт с огромным количеством функций. Но, в конечном итоге, мы поняли, что большинство функций нам не нужны, а интерфейс слишком сложный и неудобный. В результате, мы потратили много времени и денег на внедрение и настройку этого решения, а в итоге так и не получили желаемого результата. Было гораздо эффективнее разработать собственную систему визуализации, которая была бы адаптирована под наши конкретные потребности. Этот опыт научил нас не гоняться за 'красивыми' решениями, а выбирать те, которые действительно решают проблемы.
В заключение хочу сказать, что внедрение интеллектуального мониторинга устройств завод – это сложный и многогранный процесс, требующий комплексного подхода и опыта. Необходимо учитывать множество факторов – от разрозненности данных до проблем масштабируемости. Но, при правильном подходе, эта технология может принести значительную экономию и повысить эффективность производства.
Наш опыт работы с предприятиями, таким как ООО Аньхуэй Чжихуань технологии, показывает, что правильная стратегия, качественная реализация и постоянная оптимизация позволяют получить максимальную отдачу от внедрения систем мониторинга оборудования.
Соответствующая продукция
Соответствующая продукция



Самые продаваемые продукты
Самые продаваемые продукты-
 ZHW2001D Взрывозащищенный и искробезопасный беспроводной сборщик данных
ZHW2001D Взрывозащищенный и искробезопасный беспроводной сборщик данных -
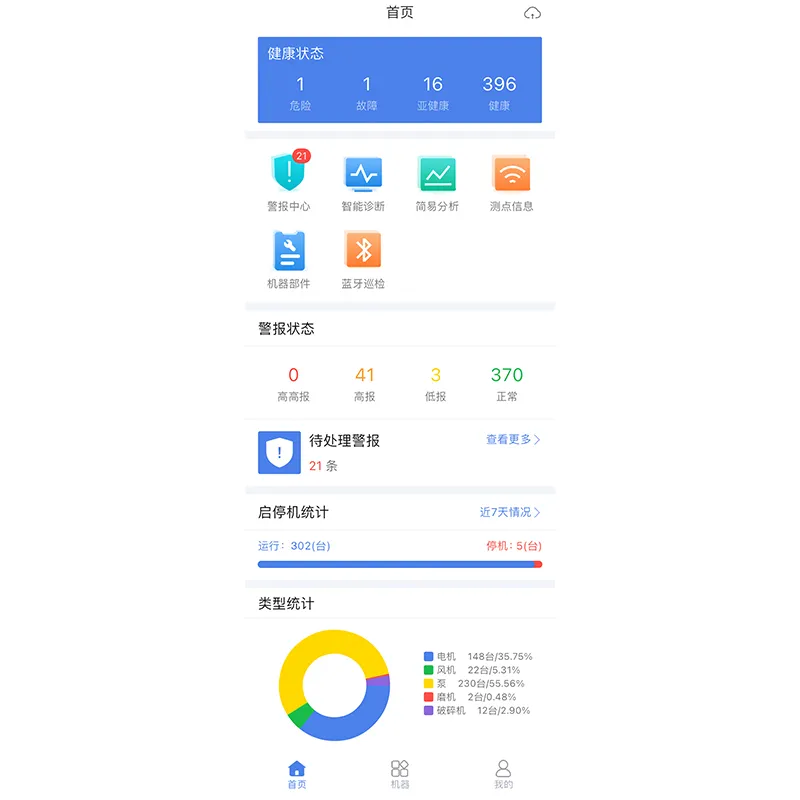 Машинная аналитика данных
Машинная аналитика данных -
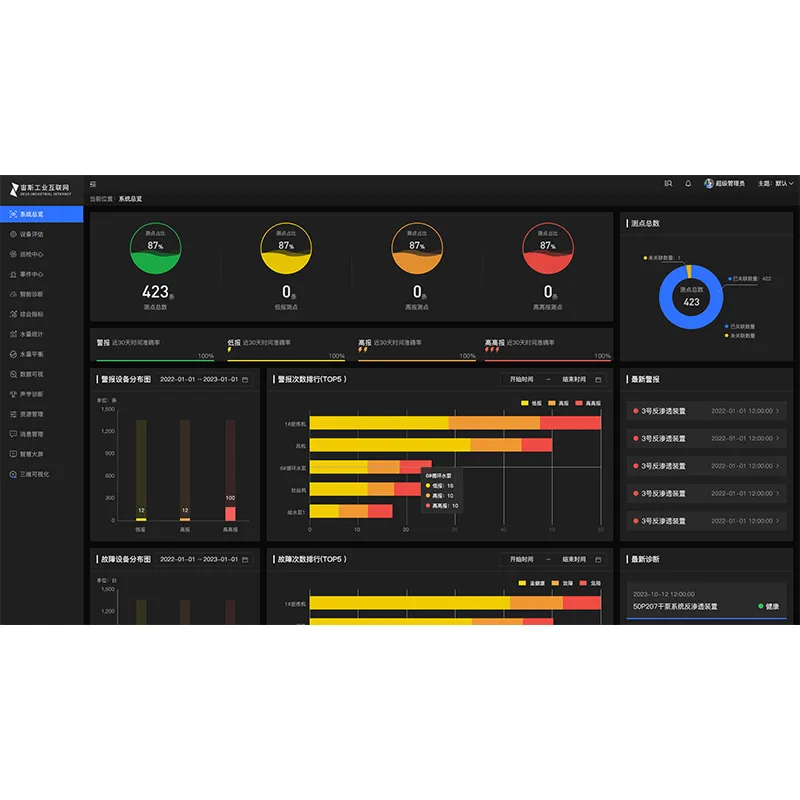 Беспилотная система инспекции
Беспилотная система инспекции -
 ZHW803P-4G Трехосный беспроводной датчик вибрации и температуры
ZHW803P-4G Трехосный беспроводной датчик вибрации и температуры -
 YJC127W Взрывозащищенный и искробезопасный беспроводной регистратор данных для использования в шахтах
YJC127W Взрывозащищенный и искробезопасный беспроводной регистратор данных для использования в шахтах -
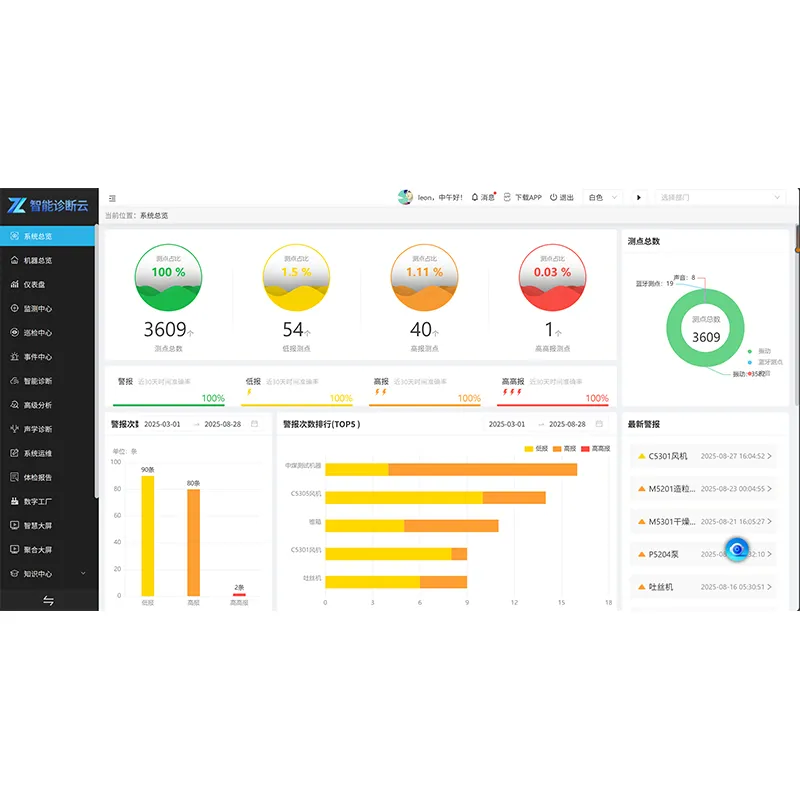 Облачная платформа диагностики машинного интеллекта
Облачная платформа диагностики машинного интеллекта -
 ZHY601(T) Проводной датчик вибрации всех частот
ZHY601(T) Проводной датчик вибрации всех частот -
 ZHW2001 Беспроводной регистратор данных
ZHW2001 Беспроводной регистратор данных -
 ZHY-1101(D)Взрывозащищенный и искробезопасный проводной регистратор данных
ZHY-1101(D)Взрывозащищенный и искробезопасный проводной регистратор данных -
 YHC12 Искробезопасный сборщик данных для горнодобывающей промышленности
YHC12 Искробезопасный сборщик данных для горнодобывающей промышленности -
 ZHW2700 Промышленный 5G-маршрутизатор
ZHW2700 Промышленный 5G-маршрутизатор -
 ZHW803P 3-осевой беспроводной встроенный датчик вибрации и температуры
ZHW803P 3-осевой беспроводной встроенный датчик вибрации и температуры
Связанный поиск
Связанный поиск- Китай использование цифрового двойника производитель
- Инфракрасный мониторинг поставщики
- Китай мониторинг безопасности персонала основный покупатель
- Китай мониторинг предотвращения разрыва ленты поставщик
- Китай инфракрасный мониторинг производитель
- Проводной датчик для акустического мониторинга основный покупатель
- Мониторинг ненормального шума оборудования цена
- Интеллектуальные алгоритмы основный покупатель
- Китай мониторинг состояния промышленного оборудования производители
- Дешево мониторинг ленточных конвейеров