





Внедрение цифрового двойника поставщик
Цифровой двойник поставщика… Звучит масштабно, наверное, даже немного футуристично. Но, поверьте, это уже не просто модное словечко. На практике, зачастую это попытка решить вполне конкретные проблемы – от оптимизации цепочек поставок до повышения предсказуемости и снижения рисков. Многие, как и я когда-то, подходили к этому вопросу слишком глобально, стремясь сразу создать 'полный' виртуальный мир поставщика. Забывали о том, что начинать нужно с малого, с реальных потребностей.
Зачем вообще нужен цифровой двойник поставщика?
Вроде бы, все понятно: видимость, оптимизация, снижение затрат. Но давайте копнем глубже. Для меня ключевая причина внедрения цифрового двойника поставщика – это снижение неопределенности. Неопределенности, связанной с возможными сбоями в поставках, колебаниями цен, изменениями в производственных планах поставщика и т.д. Раньше мы полагались на отчеты, на встречи, на интуицию. Это не всегда работало. А теперь, с моделью, основанной на реальных данных, можно не просто видеть ситуацию, но и прогнозировать ее.
Например, у нас был случай с поставкой критически важного компонента для производства оборудования. Задержка была вызвана нехваткой сырья у поставщика, о которой мы узнали только когда уже начали испытывать проблемы с производством. Цифровой двойник, если бы он был внедрен, мог бы предупредить об этом за несколько недель, позволив нам заранее найти альтернативные источники или перепланировать производство. Это, конечно, гипотетическое условие, но на практике мы сталкивались с подобными ситуациями регулярно.
Повышение прозрачности и контроль качества
Цифровой двойник позволяет получить полную прозрачность в процессах поставщика. Мы можем отслеживать не только количество товара, но и его состояние, ход производства, соблюдение сроков, контроль качества на каждом этапе. Это критически важно, особенно если речь идет о компонентах, которые напрямую влияют на качество конечного продукта.
Рассматривали вариант с использованием IoT-датчиков для мониторинга условий хранения сырья и готовой продукции у поставщика. Оказывается, температура и влажность оказывают существенное влияние на характеристики некоторых материалов. Если бы мы знали об этом заранее, могли бы потребовать от поставщика более строгих условий хранения или даже отказаться от работы с ним.
С чего начать внедрение? Не стоит сразу гоняться за 'полной картиной'
Самая большая ошибка – пытаться построить полноценный цифровой двойник поставщика сразу со всеми функциями и возможностями. Это дорого, сложно и, скорее всего, не принесет желаемого результата. Лучше начать с пилотного проекта, например, с одной узкой области, например, с отслеживания сроков поставки одного конкретного продукта.
Мы начали с анализа данных, которые у нас уже были – данные о поставках, о ценах, о качестве. Затем выявили наиболее критичные аспекты, которые нужно отслеживать. После этого выбрали технологию, которая лучше всего подходит для решения конкретной задачи. В нашем случае это была интеграция с существующей ERP-системой и использование облачного хранилища данных.
Интеграция с существующими системами
Важно помнить, что цифровой двойник – это не отдельная система, а дополнение к существующим. Интеграция с ERP, CRM, системами управления логистикой – это ключевой момент. Иначе все данные будут разрознены, и пользы от цифрового двойника будет мало.
У нас возникли сложности с интеграцией с системой учета поставщика. Оказывается, у них была устаревшая система, которая не поддерживала стандартные протоколы обмена данными. Пришлось разрабатывать специальный интерфейс для обмена данными, что увеличило затраты и сроки внедрения.
Какие технологии использовать?
Выбор технологий зависит от конкретной задачи и бюджета. Можно использовать различные платформы для создания цифровых двойников: от простых решений на базе Excel до сложных систем, основанных на искусственном интеллекте и машинном обучении.
Например, мы рассматривали варианты с использованием платформы Microsoft Azure Digital Twins. Она позволяет создавать цифровые модели физических объектов и процессов, интегрировать их с различными источниками данных и использовать для анализа и прогнозирования. Но в итоге остановились на более простом решении на базе облачного хранилища данных и API для интеграции с существующими системами. В нашем случае, более простое решение оказалось более эффективным и экономичным.
Искусственный интеллект и машинное обучение
Использование искусственного интеллекта и машинного обучения позволяет автоматизировать многие процессы, связанные с анализом данных и прогнозированием. Например, можно использовать машинное обучение для прогнозирования задержек в поставках, оптимизации маршрутов доставки, выявления аномалий в данных.
Мы планируем внедрять инструменты машинного обучения в будущем, когда у нас будет больше данных и опыт. Сейчас мы фокусируемся на более простых задачах, таких как автоматизация отчетности и мониторинг ключевых показателей.
Риски и подводные камни
Внедрение цифрового двойника поставщика – это не только возможности, но и риски. Например, риск сбора и обработки больших объемов данных, риск утечки данных, риск несовместимости с существующими системами.
Важно уделять особое внимание вопросам безопасности данных. Необходимо использовать надежные методы шифрования и защиты данных, ограничить доступ к данным только для авторизованных пользователей, проводить регулярные аудиты безопасности.
Вопросы совместимости и интеграции
Одной из самых больших проблем является совместимость данных от разных поставщиков. У каждого поставщика может быть своя система учета, своя терминология, свой формат данных. Приходится тратить много времени и усилий на преобразование данных в единый формат.
Мы использовали стандарты обмена данными, такие как EDI, для упрощения интеграции с поставщиками. Но даже при использовании стандартов, возникают проблемы с интерпретацией данных и сопоставлением информации.
Вывод: это инвестиция в будущее
Внедрение цифрового двойника поставщика – это серьезная инвестиция, которая требует времени, усилий и ресурсов. Но, при правильном подходе, она может принести значительные выгоды: снижение рисков, повышение прозрачности, оптимизация цепочек поставок, повышение качества продукции. Это не просто тренд, это необходимость для компаний, которые хотят оставаться конкурентоспособными на рынке.
Наши наблюдения показывают, что компании, которые начали внедрять цифровые двойники поставщиков раньше, сейчас имеют значительное преимущество перед теми, кто только начинает. Они быстрее адаптируются к изменениям рынка, лучше управляют рисками и более эффективно используют ресурсы.
Если говорить о практическом опыте, то я бы посоветовал начинать с малого, сосредоточиться на конкретной задаче, выбирать подходящие технологии и не забывать о безопасности данных. И, конечно, не бояться экспериментировать и учиться на своих ошибках. Потому что ошибки – это неизбежная часть любого процесса внедрения новых технологий.
Соответствующая продукция
Соответствующая продукция

Самые продаваемые продукты
Самые продаваемые продукты-
 YJC127W Взрывозащищенный и искробезопасный беспроводной регистратор данных для использования в шахтах
YJC127W Взрывозащищенный и искробезопасный беспроводной регистратор данных для использования в шахтах -
 ZHY1101 5G -версия многофункционального проводного блока сбора данных
ZHY1101 5G -версия многофункционального проводного блока сбора данных -
 ZHW801 Беспроводной интегрированный датчик вибрации и температуры
ZHW801 Беспроводной интегрированный датчик вибрации и температуры -
 ZHW2001D Взрывозащищенный и искробезопасный беспроводной сборщик данных
ZHW2001D Взрывозащищенный и искробезопасный беспроводной сборщик данных -
 ZHY601(T) Проводной датчик вибрации всех частот
ZHY601(T) Проводной датчик вибрации всех частот -
 ZHW2700 Промышленный 5G-маршрутизатор
ZHW2700 Промышленный 5G-маршрутизатор -
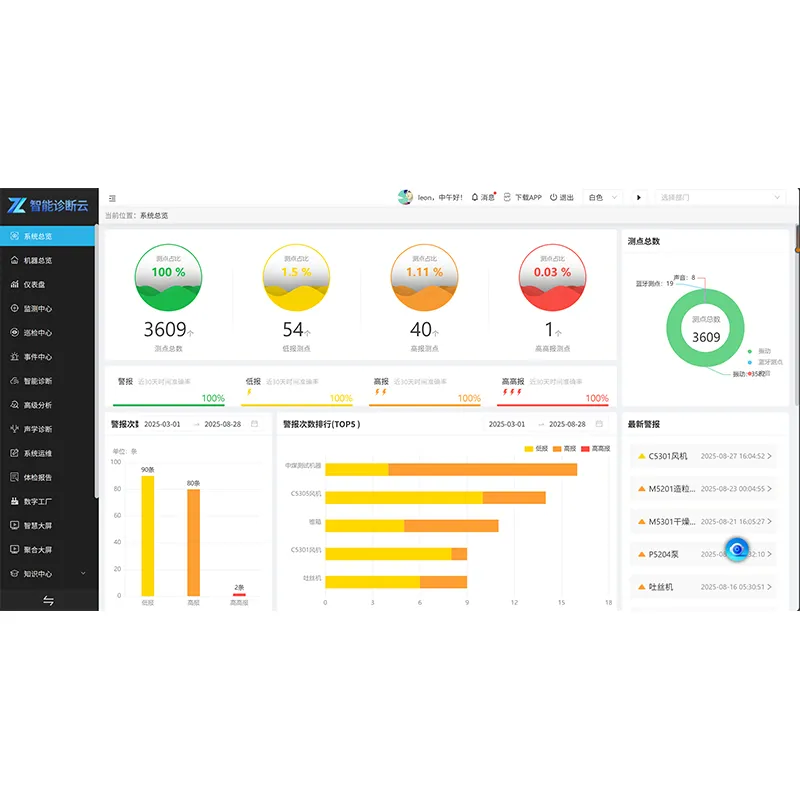 Облачная платформа диагностики машинного интеллекта
Облачная платформа диагностики машинного интеллекта -
 ZHW803P 3-осевой беспроводной встроенный датчик вибрации и температуры
ZHW803P 3-осевой беспроводной встроенный датчик вибрации и температуры -
 ZHW803P-4G Трехосный беспроводной датчик вибрации и температуры
ZHW803P-4G Трехосный беспроводной датчик вибрации и температуры -
 GBY1000W Беспроводной датчик вибрации для применения в горнодобывающей промышленности
GBY1000W Беспроводной датчик вибрации для применения в горнодобывающей промышленности -
 Беспилотная система инспекции
Беспилотная система инспекции -
 VS301 Акустический датчик вибрации и температуры
VS301 Акустический датчик вибрации и температуры
Связанный поиск
Связанный поиск- Китай применение цифровых двойников заводы
- Китай связь с облачной платформой завод
- Дешево сборщик данных
- Китай связь с облачной платформой заводы
- Мониторинг температуры и влажности основный покупатель
- Китай мониторинг беспилотного патрулирования
- Китай модели цифровых двойников производитель
- Китай разработка цифровых двойников производитель
- Китай беспилотная инспекционная система
- Проводной датчик для мониторинга вибрации поставщики